With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
“A dependent third-party network experienced an interruption to connectivity, which caused impact to the Exchange Online mailbox infrastructure.”
Customers who have deployed CloudReady were able to earlier notification and better insight into this service delivery problem, getting access to both Microsoft announcements and test data from their locations in one place.
It’s a good example of the value of CloudReady during a provider outage, so let’s walk through it.
Starting about 10:45 AM Eastern, CloudReady Exchange Online sensors started reporting problems completing login and message send transactions:

CloudReady customers that had response time alarms configured for their sensors were notified of the problems via text message, email, or through their help desk tools (via the CloudReady local logging facility).
About thirty minutes later, Microsoft reported the issue on their Service Dashboard and RSS feed:

Thirty minutes isn’t bad, given the time it takes for problems to be reported and verified, but for IT teams not equipped with CloudReady those were 30 minutes of getting calls and questions from users experiencing problems with no insight into what was happening.
As we received internal notifications errors and alarms we decided to bring up our own CloudReady console for Office 365. We’ve configured it with the new Office 365 Service Communications API features and we could see a clear correlation between Microsoft’s status messages and our own sensor observations:
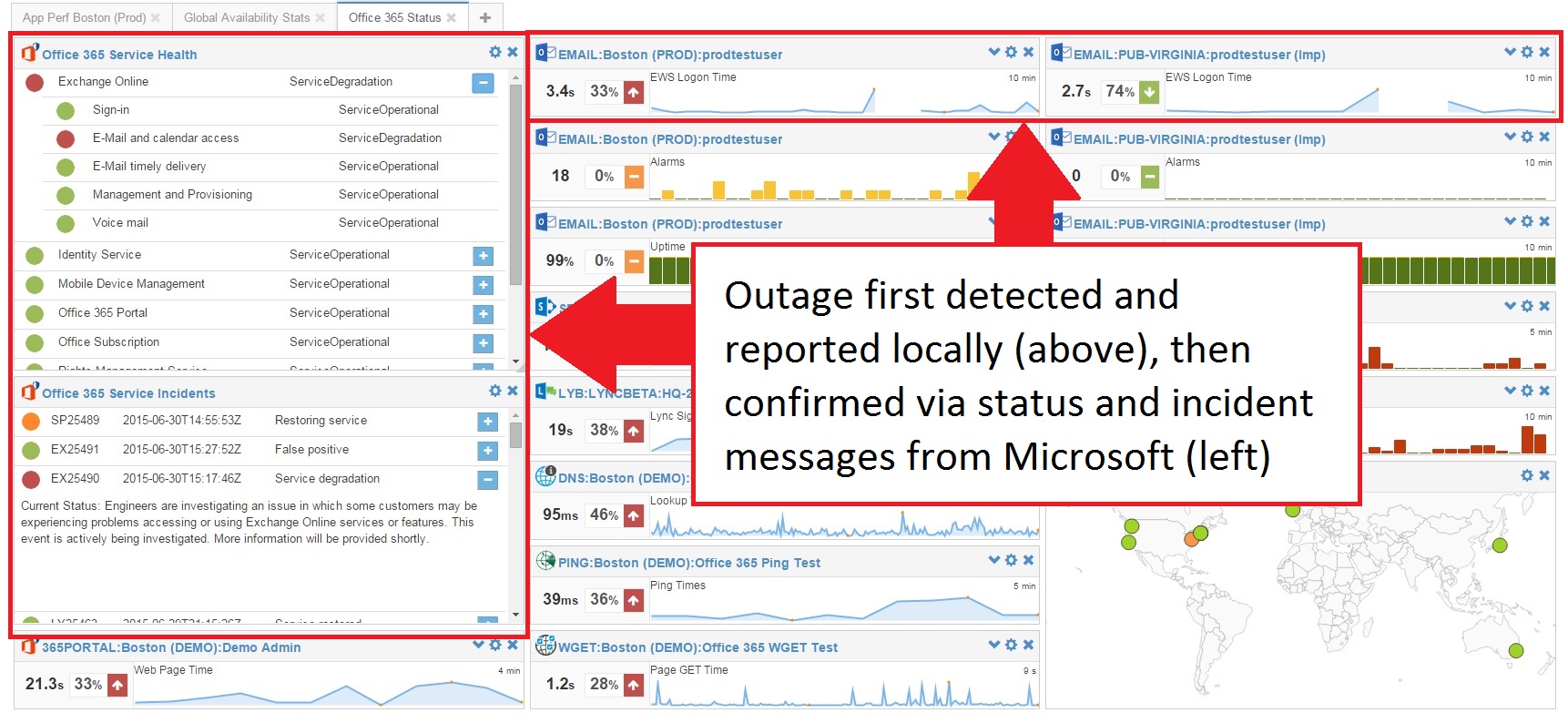
According to Microsoft, the issue resulted in sporadic behavior, with some transactions succeeding and others failing. Digging into the crowd response time data form message delivery you can see that there was an overall degradation in performance during this period.
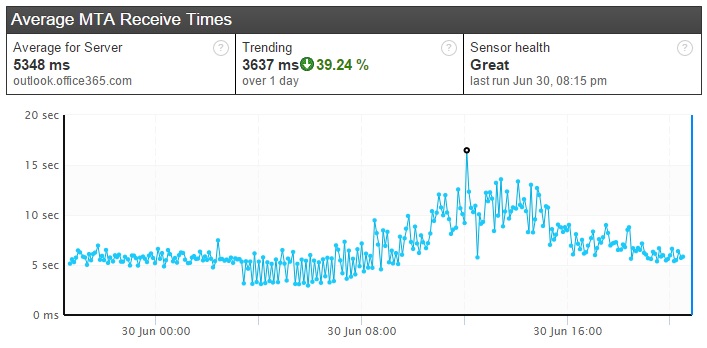
Looking at this graph you can see that thing may have been starting to degrade as early as 4 am Eastern, even before the first transaction timeouts, and that by 8pm things were almost back to normal.
One thing that came as someone of a surprise is shown in the graph below.
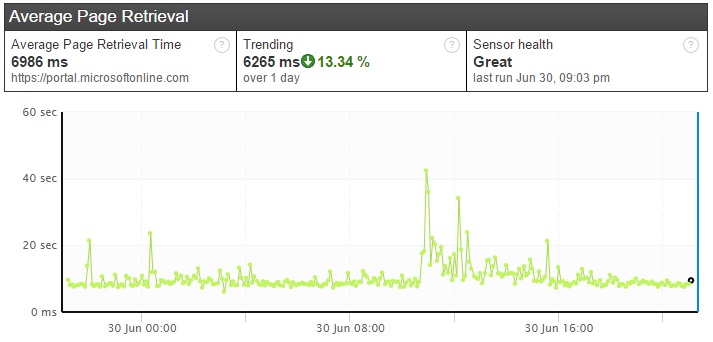
This graph shows response times from the Office 365 portal, and you can see a significant spike in values corresponding with the Exchange Online values. In this case, there was no indication of a systemic problem from Microsoft. This may in fact be reflection of the additional load on the portal due to customers logging in to get status information for the Exchange Online problem.
What does this mean for an IT team? If the problem is with Microsoft infrastructure and they can’t fix it, is there value in getting these alerts and data? Absolutely, and for several reasons. First, when issues happen “I don’t know” is not an acceptable answer when users…or the CIO…demand to know why their critical cloud app isn’t working. There’s a big difference between thinking a problem is outside your control and knowing that it is, especially since most issues will likely be something in your control to fix.
Second, even when the problem will ultimately need to be addressed by your cloud or network vendors, somebody still needs to be proactive to get the ball rolling. The sooner you detect, verify, and report an issue, the sooner they’ll be able to get things fixed.
Finally, even when you do get status reports from your vendors, verification of impact on your users is still important. As one CloudReady customer put it:
“We received performance impact reports from Exoprise in advance of any notification from Microsoft. Also, sometimes more importantly, we are able to show that alerts from Microsoft are not affecting us.”
That visibility and ability to verify impacts to their users is what allows them to fully embrace cloud based apps with confidence that they aren’t flying blind.
Related Posts


