With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
Unfortunately, Microsoft and Office 365 suffered their second major outage of the year and this one was even bigger than the first. We say “unfortunately” because even though our business is to help monitor cloud and SaaS services and our business goes up when there are problems, we don’t wish an outage on any cloud provider. Operating a SaaS business at the scale of Microsoft Office 365 is a herculean task and that’s why they get paid the big bucks. Let’s learn what caused Office 365 outages in 2019.
January 24 Outage: Mailbox Access and EX172491 Outage
Starting on January 23 and increasing into January 24th, some tenants particularly in Europe had difficultly accessing their mailboxes through multiple protocols. Users reported problems with slow e-mail sending and receiving, missing e-mails. With delays of up to 3 hours how can you even tell? On January 24th at 1:53 AM, the official Microsoft Twitter account which delivers updates on Microsoft 365 service incidents tweeted the following:
We’re investigating an issue where users can’t access their mailboxes through multiple protocols. More details are published in the admin center under EX172491, available to your Microsoft 365 admin.
— Microsoft 365 Status (@MSFT365Status) January 24, 2019
According to Exoprise telemetry, from our own customers, the problem started about 90 minutes earlier and not all tenants were affected. Often, Microsoft may indicate that a problem doesn’t affect all tenants when it really does (its boilerplate) but in this case, the issue really didn’t affect all of the the tenants. At least from the perspective of CloudReady for Office 365.
After a few hours Microsoft put out the following tweet:
We’ve determined that a subset of Domain Controller infrastructure is unresponsive, resulting in user connection time outs. We’re applying steps to mitigate the issue. More details can be found in the admin center published under EX172491.
— Microsoft 365 Status (@MSFT365Status) January 24, 2019
Needless to say, there was some frustration on behalf of European customers for the inability to get to their mailboxes. After two days of downtime for the affected users, Microsoft finally resolved the issue:
We’ve deployed some fixes and made some configuration changes throughout the affected infrastructure. Things are looking good so far but we’ll monitor throughout the day to ensure the service remains healthy. For more updates refer to EX172491 in the Admin Center.
— Microsoft 365 Status (@MSFT365Status) January 28, 2019
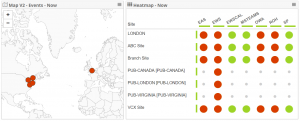
Here’s an example of what the CloudReady dashboard looked like for one of our tenants. Some of the site names have been changed. Most of our customers were notified via alarms and on-premises system integrations well in advance of users reporting problems. Their tenancy is Europe based so even cloud-based sensors were reporting Exchange Online issues from far off places due to the nature of the outage.
January 29th Outage: Azure AD, Dynamics 365, Skype, DNS, SafeUrls and More
On January 29th, Office 365 suffered its second outage of the new year and this one was worse, affecting more people and more subsystems and was not just relegated to European customers. Ultimately, DNS problems and Azure Active Directory caused the most problems but there were lurking signs of issues earlier on and a change to infrastructure may have been the straw that broke the camels back. The causes are still being sussed out.
Here’s a brief timeline of what our customers saw, the tweets and notifications from the Office 365 Service Health.
10am EST January 29th
Starting early on January 29th, many customers were reporting issues with Safe URLs or ATP Safe Links. This feature is designed to scan URLs when they are accessed from email messages from Outlook, Outlook Web Access or the Mobile Apps. Users were reporting HTTP 503 Error codes why trying to click to access the URLs.
We’re investigating an issue where some users are unable to access URLs from emails.
— Microsoft 365 Status (@MSFT365Status) January 29, 2019
Our customers were immediately made aware of the issue through our Office 365 Service Health Integration via email and webhook distribution as well as integrated dashboards. It looks like Microsoft assigned this issue, ID: EX172674 but some customers report not being able to see this in their feeds or admin portal.
Continual Skype for Business Issues, Dropped Calls Throughout January 28th and 29th

At the same time, over the previous days starting during the weekend, there had been various reports about Skype for Business dropping calls. This ticket, with ID: LY172650, transitioned to many different states going into Monday (1/28) and Tuesday (1/29) but it seemed like Microsoft was unable to determine the cause of the issue. States of the ticket changed from False positive to real issue, back and forth. Ultimately, yesterday at the same time as the other issues were occurring, Skype for Business was widely interrupted. Its likely that DNS related issues were affecting call dropping as, ultimately, infrastructure changes caused a widespread DNS outage.
21:00 UTC, DNS Outages, Microsoft Azure Active Directory (AAD) Problems Start to Increase
Later in the day as Microsoft engineers were continuing to wrestle the ATP Safe Link problems, they indicated that a change to infrastructure was coming and that the engineers had planned to “reroute” traffic to alternative infrastructure. Here’s the quote from ticket EX172674:
Current status: We’re continuing to reroute traffic through alternative infrastructure, and our testing indicates that service functionality is improving. Additionally, our analysis has led us to narrow the focus of our investigation to a subset of Safe Link infrastructure that is not operating as expected as we work to isolate the underlying cause of impact.
While Exoprise can’t be sure of what came first, the 503 blocking of URL access or the re-routing of access to these services, we suspect that the changes may have caused larger scale outages related to DNS which was ultimately assigned to Level 3 Communications problems. See this tweet from Azure Support at 4pm EST:
??Starting at 21:00 UTC on 29 Jan 2019, customers may experience issues accessing Microsoft Cloud resources. Engineers are pursuing multiple workstreams to isolate the root cause and mitigate impact. The next update will be provided in 60 minutes or as events warrant.
— Azure Support (@AzureSupport) January 29, 2019
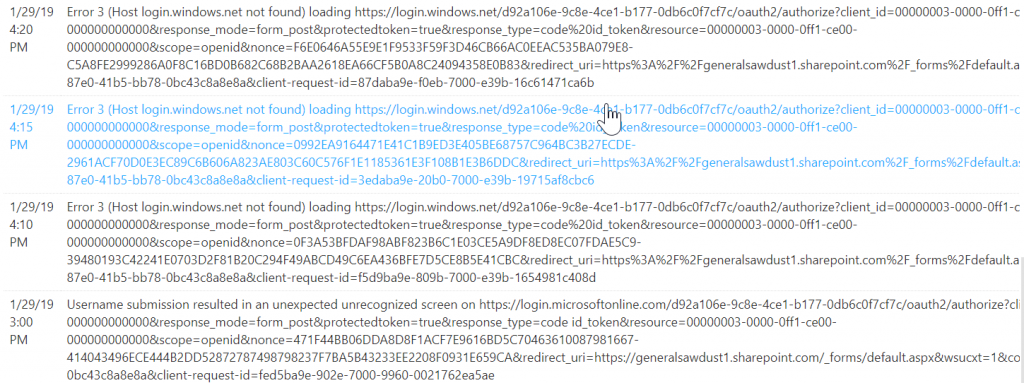
Exoprise Customers started to see significant error rates across a wide array of sensors including SharePoint, OWA, OneDrive, Skype, Teams and Exchange Online. Every customer that had US-based federated integration with Azure Active Directory started to have DNS resolution problems. Our customers saw this in advance of Microsoft reporting any issues and, generally, in advance of end-users reporting problems. End-users that weren’t signed out had less problems. Most CloudReady sensors perform a full login each time which tests the Single Sign-in infrastructure each time. Here’s an example of the errors that SharePoint were generating:
Microsoft “Switches” to An Alternative DNS Provider
About 30 minutes after the DNS outage started, customers started to see some of the DNS lookups start to resolve. Microsoft confirmed that they had changed to an alternative DNS provider for resolving critical AAD naming.
??Engineers have taken steps to fail over to an alternative DNS provider, which has partially mitigated impact. Engineers continue to pursue additional mitigation paths to ensure full recovery. Up-to-date information can be found on the SHD: https://t.co/Dw19fIGsXf
— Azure Support (@AzureSupport) January 29, 2019
In various tweets, before or after, Microsoft indicated that the source of the problem was with Level 3 communications, a large US-based ISP that provides connectivity and various other services to Microsoft data centers:
“Engineers have identified an issue with Level 3 as an internal network provider. Steps have been taken to fail over to an alternative DNS provider.”
30 Minute DNS Outage Contained but Lots of Surrounding Mystery
By 22:00 UTC on January 29th, federated login and access to Windows services seem to recover. Its still not clear what came first with this outage. Was it a subtle DNS problem that started during the weekend affecting Skype calls, then Exchange Safe URL / ATP SafeLink system? Were the attempts to fix these infrastructure issues, by re-routing traffic via alternative DNS which caused the more onerous authentication outage? Time may tell with more investigative reports and we will update this article as we learn more.
Update February 5th, 2019: It looks like early indications of problems via Skype / Microsoft Teams usage and infrastructure were, indeed, part of the same escalating outage. Microsoft recently published an update to incident: LY172785 which confirms.
Preliminary root cause: A recent update to components that facilitate communication between some back-end services leveraged by Skype for Business and Microsoft Teams adversely affected how our service handles calling and conferencing traffic during peak hours. This update took effect within our environment concurrently with an outage experienced by our Content Delivery Network (CDN) partner, delaying our response to the regression introduced by the update described above.
Related Posts


