With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
Is Microsoft 365 down?
Unfortunately, in this time of increased dependency on Microsoft Teams, Zoom and other remote conferencing solutions while working from home, Microsoft 365 had a Teams Audio/Video Conferencing outage between August 19th and 20th of this year. Fortunately, for Exoprise customers, they were able to detect the outage, learned of it many hours before Microsoft reported the outage and were able to stay informed as to when it was fixed.
For many institutions they could choose a different platform in the interim to continue to collaborate and get their work done. Knowing in advance of a Microsoft Teams incident helps IT teams keep end-users and leaders informed. In this article, we’ll cover the way the outage manifested itself in Exoprise CloudReady, a bit of the timeline, and the final resolution of the outage.
Start of Teams Outage, Exoprise Detects Many Hours in Advance
Microsoft’s Preliminary Post Incident Report for Microsoft 365 for this outage or incident (TM220645) details that the outage started on Wednesday, August 19, 2020, at 2:10 PM UTC. That’s their “official” start of the incident. In their own post incident report, they convey that they didn’t officially detect the issue until 2:43 PM UTC. That’s a 30 minute lag time between when the outage occurred and when their own systems detected the outage:
2:43 PM – Anomaly detection systems indicated an issue with Microsoft Teams and we started to investigate.
2:56 PM – We received multiple customer reports of a potential issue with users being unable to join Microsoft Teams meetings.
3:00 PM – We started a high-priority investigation and started to determine the scope of impact.
3:11 PM – Impact appeared to be isolated to meetings hosted in North America.
Outage Began Even Earlier
According to the Exoprise CloudReady Teams AV Sensors, the outage began quite a few hours before. Starting at 3:25 AM UTC, almost 12 hours before Microsoft even reports knowledge of the outage internally, Microsoft Teams began dropping conferences in the Northeastern Region. See the chart, where we have a Teams AV sensor running in California that is connecting to our Northeastern tenant.
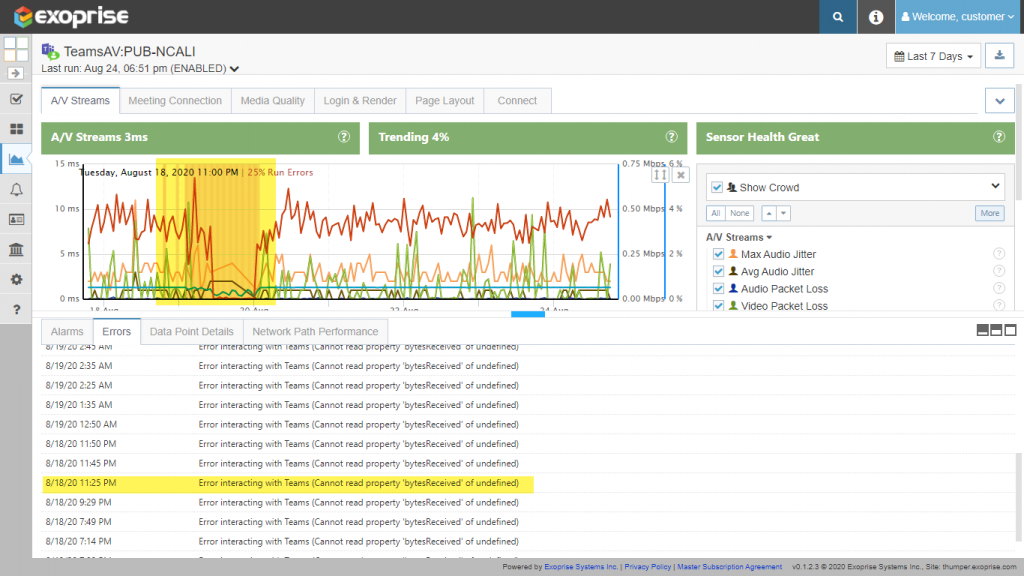
This was a new type of outage detected by the Teams AV Sensor and we are working to improve the telemetry and error messages. In this case, the Exoprise Teams Audio Video Bot was beginning an invite and joining the conference to began streaming the Audio and Video so that the sensor could detect the end-to-end performance and capture metrics. In this outage case the streaming session was immediately interrupted and dropping. The audio/video conference with the Exoprise BOT usually lasts for between 60 and 90 seconds (to capture enough telemetry in the session) but in this case it lasted just 6 (six) seconds. This prevented any valuable statistics from being generated and that is the error message being reported.
You can read more about the operations of the Exoprise Teams AV Conferencing Sensor.
At this time, we also periodically saw HTTP status codes from the Microsoft Communications Graph API that returned 410. HTTP Status Code 410 is simply Gone and implies that calls are being dropped. We are still evaluating and trying to reproduce this error code. The engineering team at Exoprise didn’t see this error condition consistently and so are trying to better understand whether its an even earlier indicator or an anomaly itself.
Lastly, you can see from the image that the condition of dropped calls started even earlier than what we are considering the real start of the outage. Dropped conferences began as early as 3 or 4 hours before 3:25 UTC but they weren’t every 5 minutes and were only periodic at that point.
Fixes Deployed, Detected Immediately
In the post incident report Microsoft indicates that they consider the end time of the end of the incident to be 5:49 AM UTC. See the last bit of timeline from the report.
2:48 AM – We determined that the root cause was as a problematic feature used for automated traffic-management and resource CPU utilization.
5:44 AM – We started to reconfigured the LowCPUMode thresholds for the affected service components to ensure that the problem would not reoccur during the next increase of traffic expected during US business hours.
5:49 AM – We completed reconfiguring the LowCPUMode thresholds. Due to the issue manifesting during peak load, we agreed to continue to monitor the service throughout US business hours before confirming resolution.
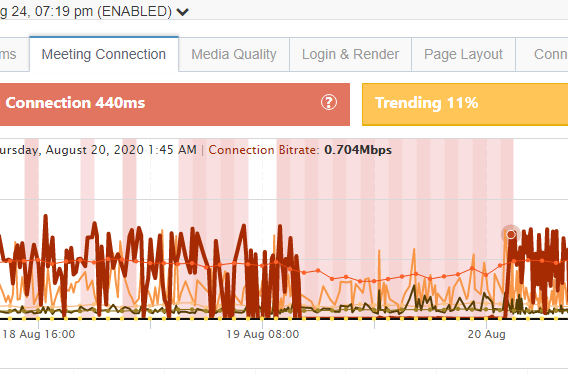
This timeline for the resolution of the issue completely coincides with the Exoprise Teams Monitoring that our customers had in place. This is important because Exoprise customers can rely on and confirm that the data that is being generated and collected from the Exoprise sensors matches the timeline and updates from the integrated Microsoft 365 Service Communications status messages. Here’s a zoom in on the recover which coincides with August 20th, 1:45 AM Eastern time.
“Optimization” Often The Source of Problems
Microsoft detailed the root cause in their Post-Incident report and it appears to be some optimization that they had put in place though its not clear if this was new optimization or newly triggered. Operating an Audio Video conferencing system at scale is no easy feat and requires continuous resource optimization to ensure the service can be effectively delivered. These kinds of changes are necessary and continuous. In this case it was the culprit for the outage.
Root Cause
A new feature which automatically triggers the process for components to enter a LowCPUMode when operating at a combination of; a specific Central Processing Unit (CPU) utilization rate and active connected user count, inadvertently caused impact.Once a component enters the LowCPUMode, additional connections are redistributed to alternate components throughout the environment, until the CPU utilization rate and active connected user count reaches predefined safe thresholds. Due to an unexpected spike in North American Teams meeting requests, components started to enter LowCPUMode to self-recover. However, components were not leaving LowCPUMode at expected levels. This resulted in a cascading effect where fewer service components were available to process an increasing number of requests, resulting in additional components reaching the CPU thresholds and entering LowCPUMode mode quicker. During the peak of impact, only 13% of overall regional service components were able to accept new requests.
Early Detection, Confirmation of Microsoft Teams Outage
This is another example of utilizing Exoprise to detect Microsoft 365 outages hours in advance through the use of CloudReady. Ensure effective communications among your IT leaders and teams, recover lost service credits and optimize your incident handling. Start a free trial today.
Related Posts


