
With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
On the morning of September 4th, 2018 a number of customers experienced sign-in problems related to an outage for Azure, Azure AD and, in turn, Office 365. The issue was caused by an outage in Microsoft’s South Central U.S. datacenter. The problem ended up affecting customers in other regions, too, as we will see. Most Exoprise customers knew of the growing problems throughout the morning, well before, the Office 365 service health status pages were updated with notifications about their tenants and well before telemetry appeared else within the Azure Twitter feeds and status pages.
U.S. South Central Datacenter Loss
It was later reported that a lightning strike in the San Antonio, Texas are may have caused the cooling system to go down in the Microsoft’s datacenter in that region. At 9:31 AM ET a tweet from the Azure Support twitter feed indicated that engineers were working on a resolution for this affected datacenter. Finally, some indications of the cause of the problem started to arrive about an hour later, at around 10:25 AM ET. The history of the event is available from the Azure Status History Page and a screenshot is captured here for posterity.
Starting at 09:29 UTC on 04 Sep 2018, customers in South Central US may experience difficulties connecting to resources hosted in this region. Engineers have isolated an issue with cooling in one part of the data center, which caused a localized spike in temperature, as the preliminary root-cause, which has now been mitigated. Automated data center procedures to ensure data and hardware integrity went into effect when temperatures hit a specified threshold and critical hardware entered a structured power down process. Engineers are now in the process of restoring power to affected devices as part of the ongoing mitigation process.
“Some services may also be experiencing intermittent authentication issues due to downstream Azure Active Directory impact, and engineers are separately working on mitigation options for this also.
“The next update will be provided at 15:00 UTC or as events warrant.”
What Our Customers Saw
Starting about 7 AM ET, for most of US customers, they received outage alarms from their CloudReady Sensors via email, Twilio, integrated on-premises alarm publishing. Depending on coverage, where they have CloudReady Private Sites installed, and what types of monitoring they had deployed, their dashboards began to “light-up” with alarms. Here’s some clips from what our dashboards looked like during the outage:
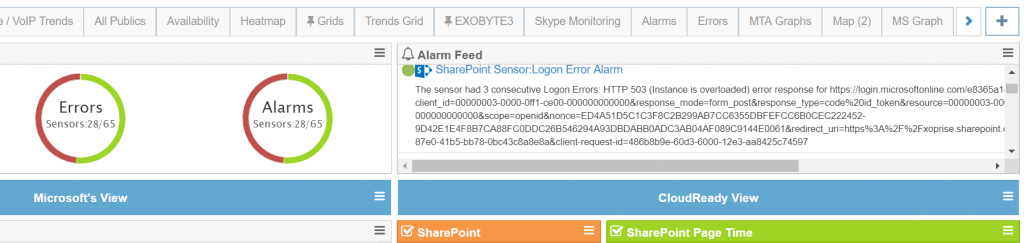
This was well before any status updates from the Admin portal, from the Office 365 Service Communications Messages and, thankfully, well before customers were in their East or West Coast offices arrived to begin the day.
Diving Deeper
For our own internal CloudReady deployment, we could see that sites and sensors located outside the US were having fewer problems than those that reside in the U.S. Additionally, we could see that it was a sign-in / Azure AD related issue and not one with the back-end data-center servers, mailboxe servers, SharePoint, Teams, or Yammer sites. We also knew that it was related to sign-in and web access as opposed to API access due to the diversity of our deployment and coverage.

Later in the morning, at around 11am ET, the Office 365 service health status page was updated indicating that SharePoint, Exchange, Power BI, Teams and Intune users all may be affected. We, and our customers, knew this already and from the various error message reported, it was clear that Azure AD was trying to recover but that there were capacity and higher than normal latency problems. Here’s a sample of the error messages that were variously generated and some explanations.
Example Error Displays from a SharePoint Sensor
Once customers were notified of errors through the notifications and integrations with various systems like Splunk and SCOM, they were able to drill down through to our various screens to surface more contextual information about the errors, the time periods and they quickly could see that the crowd was also experiencing slowdowns. This is an indicator that the problem was not tenant specific but, rather, one that was affected multiple tenants and Microsoft services more broadly.
Filtering different sensors by the various regions where we have sensors deployed enable us to see that sign-in and Azure AD performance was affected for the U.S. locations versus internationally deployed sensors at Public Sites.
[content type=page name=cta_chr_office_365 status=private]
Various Errors Reported By CloudReady
You can see that the sign on and access troubles started earlier than most reports and the errors give clear indications of capacity overloading issues. This gave our gave our customers early notice of the problem and enabled them to forward/create incident reports, notify their operations and help-desk staff well in advance of any end-users reporting the problem. Preparation and early detection is critical when it comes to cloud outages.
| 9/4/18 1:29 PM | Timed out during login, URL: https://xoprise.sharepoint.com/SitePages/Home.aspx |
| 9/4/18 12:49 PM | HTTP 503 (Instance is overloaded) error response for https://login.microsoftonline.com/exxxxxxxx-503f-4e20-b643-xxxxxxxx/login |
| 9/4/18 12:14 PM | Timed out during login, URL: https://xoprise.sharepoint.com/SitePages/Home.aspx |
| 9/4/18 12:04 PM | Timed out during login, URL: https://xoprise.sharepoint.com/SitePages/Home.aspx |
| 9/4/18 11:14 AM | HTTP 504 (Gateway timeout.) error response for https://login.microsoftonline.com/exxxxxxxx-503f-4e20-b643-xxxxxxxx/oauth2/authorize?client_id=00000003-0000-0ff1-ce00-000000000000&response_mode=form_post&response_type=code |
| 9/4/18 7:59 AM | HTTP 503 (Instance is overloaded) error response for https://login.microsoftonline.com/exxxxxxxx-503f-4e20-b643-xxxxxxxx/oauth2/authorize?client_id=00000003-0000-0ff1-ce00-000000000000&response_mode=form_post&response_type=code |
| 9/4/18 7:49 AM | Username submission failed: There was an issue looking up your account. Tap Next to try again. |
These errors were evident in all U.S. based sensors whereas sensors operating in regions outside the U.S. were unaffected at that time. You can also see that the errors started well before being reported by anyone including the Azure Support feed and the Office 365 Service Health Status. Just as important, you can see that sign-in, capacity and latency issues caused some challenges throughout the day, even after resolution issues delivered from the respective Azure and Office 365 teams and their built-in notifications.
Microsoft Services Performed Admirably
Microsoft and their data-center infrastructure performed admirably. Traffic began routing away from the affected regions almost immediately (we surmise) and it appears as if capacity was added through the day. Once they isolated the issue, they did a good job communicating so you knew they were working on it. But even updating their status, twitter feeds, and reporting dashboards takes precious time. Exoprise customers knew of the outage well before telemetry existed for the problem and our customers could immediately see that it was an outage for the crowd as opposed to one that was isolated just for their own organization.
What If This Wasn’t a Microsoft Problem?
Do you have the right tools to tell the difference? CloudReady empowers you with the visibility, speed, and agility to respond to ANY issue. CloudReady always detects issues like this one, usually long before you’ll see a service communication from Microsoft. Granted, you cannot fix issues like this. But CloudReady also isolates ANY problem end to end, ALL of which you can communicate to your users, and MANY of which you CAN fix.
Related Posts


