With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
Is Microsoft Azure Down?
Just about 2 weeks after its most recent outage, Microsoft experienced a severe DNS outage Thursday Evening at approximately 21:30 UTC on 01 Apr 2021. That’s the official start of the outage from Microsoft. But we all know that official starts and actual starts are often different.
Exoprise DNS and server monitoring caught the error about 10 minutes earlier (not our biggest amount of headroom for an outage) but that is frequently the nature of DNS failures.
Here’s the scenario we saw though all involved (us, Microsoft, others) are still investigating the issue and recovering bits and pieces of ourselves.
Early Detection of Microsoft Azure DNS Outage
At 21:20, we received an alarm Email from our Exoprise CloudReady Monitor proactive monitoring of DNS:
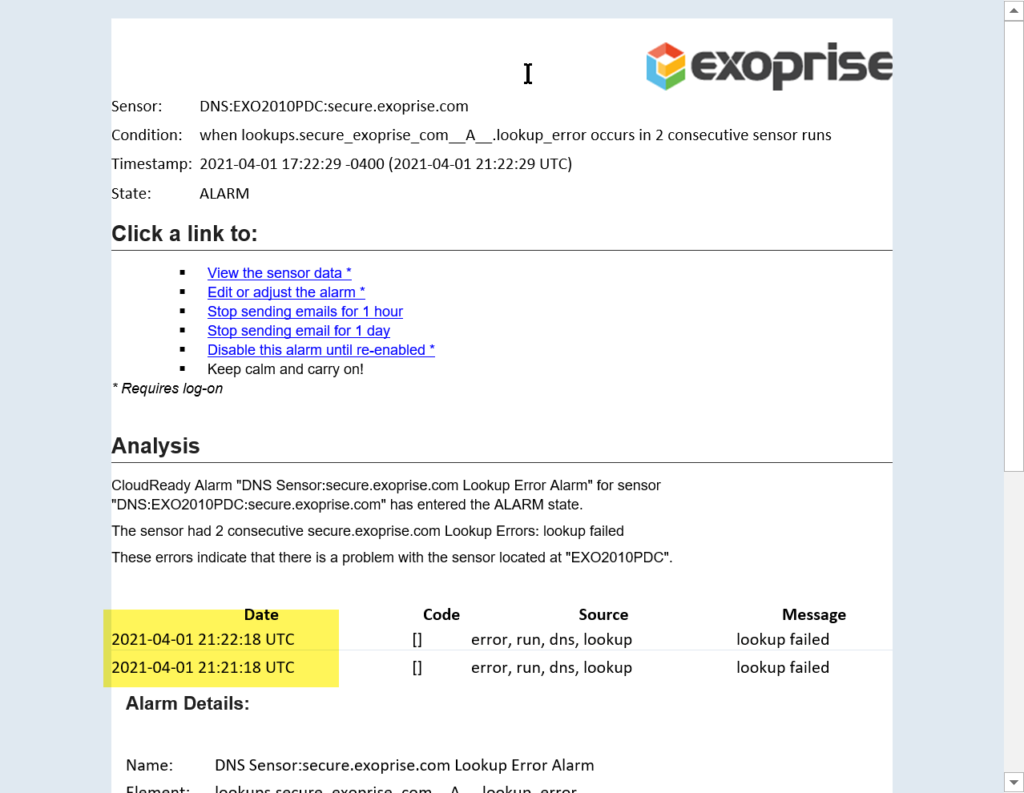
That was the first and earliest sign that all hell was about to break loose.
If there’s one lesson you need to take away from this outage it’s that DNS failures hurt and hurt bad. So, know your Azure DNS IP addresses and have them written down or exported. That might at least give you a fighting chance of getting to your infrastructure.
Azure DNS Outage Status, What Status??
You know you have a problem when your status page goes bad and you have to suggest that people use an alternative status page. And then you know its really, really bad when the second status page also goes down. That’s what happened here, doh:
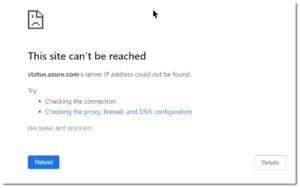
Shortly after that, someone at Microsoft started to get the picture that a static page with a message would be the way to go and they updated the status page and just published it. Here’s what we got:
Microsoft Azure, the server software that powers Xbox Live, Teams, Outlook, and other web services has gone down.
“We are aware of an issue affecting the Azure Portal and Azure services”, the official Microsoft Azure account tweeted. “Please visit our alternate Status Page … for more information and updates.”
The issue appears to be also affecting Microsoft’s other products, including Skype, OneDrive, and its Office 365 workplace suite.
Then the Exoprise Integrated Twitter status feeds started to have a semblance of information Twitter thread, saying: “We’re investigating an issue in which users may be unable to access Microsoft 365 services and features. We’ll provide additional information as soon as possible.” and the Office status page finally got a few updates too; “DNS issue affecting multiple Microsoft 365 and Azure services”, the company’s status page currently informs readers. “Users may be unable to access multiple Microsoft 365 services and features”
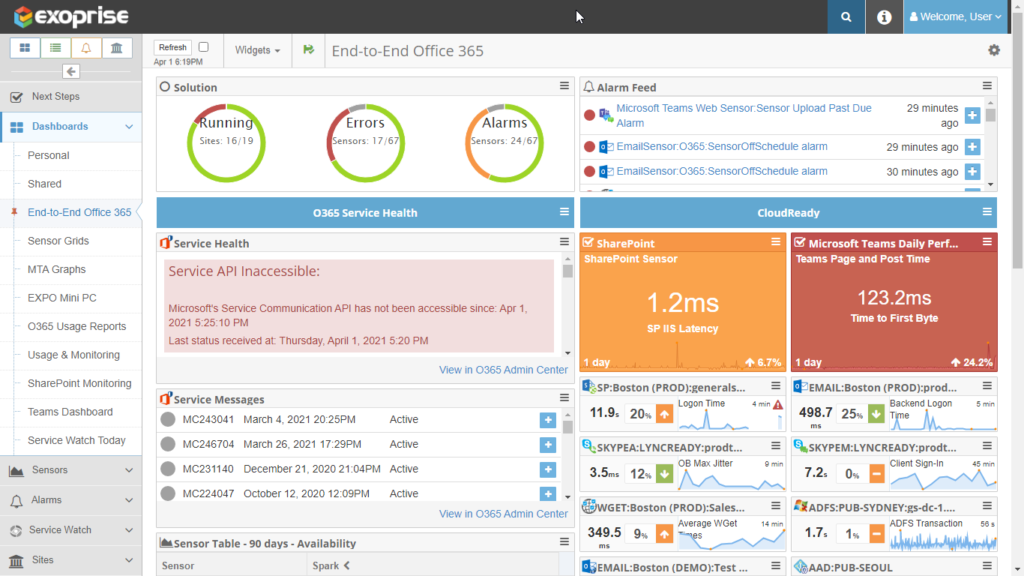
Track Azure DNS Service Outage in Exoprise Monitoring Dashboard
And our customers dashboards began to go red:
Azure DNS Issue: MO248163 Comes To Light
Sometime around 7:32 PM Eastern Time (11:32 PM UTC) Microsoft created Service Communication Message MO248163 to formally track this outage for Microsoft 365 and Azure. Since Exoprise publishes these outage through its communications, we were still up and able to communicate this to our customers:

DNS issue affecting multiple Microsoft 365 and Azure services User Impact: Users may be unable to access multiple Microsoft 365 services and features. More info: Reports indicate that impact is primarily to Microsoft Teams, though other Microsoft 365 and Azure services may be affected. Additional affected services include but are not limited to: Dynamics 365, Microsoft Intune, Skype, SharePoint Online, Exchange Online, OneDrive, Yammer, Power BI, Power Apps, and Microsoft Managed Desktop. Current Status: Microsoft rerouted traffic to our resilient DNS capabilities and are seeing improvement in service availability. We are continuing to see availability improvements, so some customers may begin seeing services recover. We are managing multiple workstreams to validate recovery and apply necessary mitigation steps to ensure complete network recovery. Scope of Impact: This issue may impact any user attempting to access multiple Microsoft 365 services and features. Next Update: Friday, April 2, 2021 by 12:00 AM UTC
You can see that this outage affected a large number of dependent and downstream services.
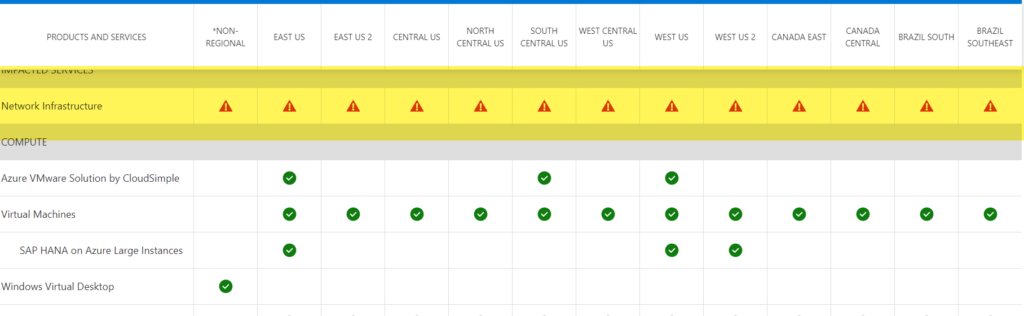
Preliminary Root Cause of Microsoft Azure DNS Outage
Friday, April 2, 2021 by 3:00 AM UTC Preliminary Root Cause: We are continuing to investigate the underlying cause for the DNS outage but we have observed that Microsoft DNS servers saw a spike in DNS traffic. Next Steps: We apologize for the impact caused by this outage. We are continuing to investigate to establish the full root cause.
So far, as of April 2nd, Microsoft is still sticking to the “spike” story. We will update this page when we have more detail and analysis to report.
More Findings
On Saturday morning, April 3rd, Microsoft published additional information though there is still no concrete information about who or what caused the surge of Azure DNS traffic. Was it a Denial-of-Service Attack (DDOS)? Was it an error or mis-configuration of DNS services? We will post more information if any is provided.
Root Cause: Azure DNS servers experienced an anomalous surge in DNS queries from across the globe targeting a set of domains hosted on Azure. Normally, Azure’s layers of caches and traffic shaping would mitigate this surge. In this incident, one specific sequence of events exposed a code defect in our DNS service that reduced the efficiency of our DNS Edge caches. As our DNS service became overloaded, DNS clients began frequent retries of their requests which added workload to the DNS service. Since client retries are considered legitimate DNS traffic, this traffic was not dropped by our volumetric spike mitigation systems. This increase in traffic led to decreased availability of our DNS service.
Mitigation: The decrease in service availability triggered our monitoring systems and engaged our engineers. Our DNS services automatically recovered themselves by 22:00 UTC. This recovery time exceeded our design goal, and our engineers prepared additional serving capacity and the ability to answer DNS queries from the volumetric spike mitigation system in case further mitigation steps were needed. The majority of services were fully recovered by 22:30 UTC. Immediately after the incident, we updated the logic on the volumetric spike mitigation system to protect the DNS service from excessive retries.
This information can also be found here: https://status.azure.com/en-us/status/history/
Microsoft 365 Outage History
Exoprise has successfully been able to detect several service outages in the past
- Microsoft 365 Outage on 15th Mar 2021
- Exchange Online mail delivery outage on 3rd Feb 2021
- Office 365 outage on 27th Jan 2021
- Microsoft 365 Teams Outage on 19th Aug 2020
Visit our Office 365 Outage Detection Page to learn more.
Besides, watch our product video to monitor ALL of Microsoft 365 include Azure AD.

Monitoring Tool for Microsoft Azure Service and Outages
You can always visit us at www.exoprise.com and learn more about how we help teams like yours manage outages successfully
But don’t wait and request a demo of our digital experience monitoring solution.
Related Posts


