
With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
Microsoft Teams Adoption On the Rise
Are you looking to optimize Microsoft Teams performance? or Do you keep asking yourself – why is Microsoft Teams so slow? Then you need a solid Teams Monitoring tool.
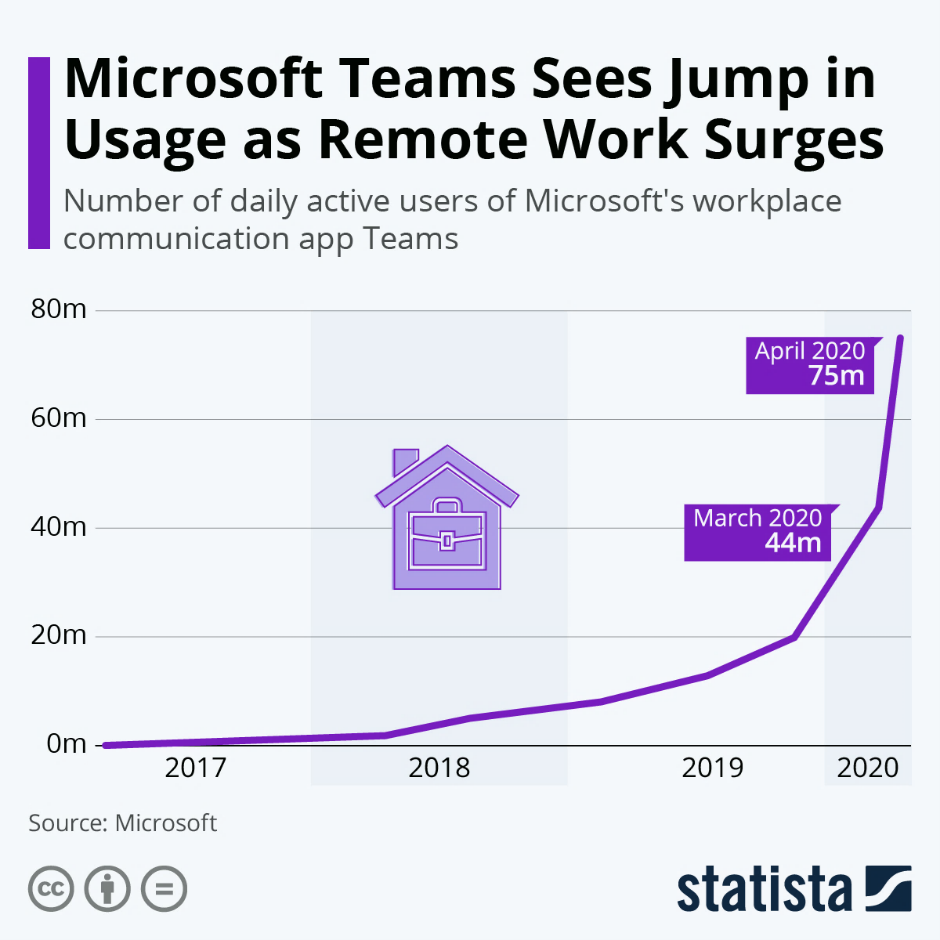
Teams is everywhere. Not surprisingly, during the pandemic, the number of daily active users for Teams increased to 75 million in 2020. More and more people are WFH and companies are becoming virtual. Personal meetings are fading now, and Teams poises to become the next best collaboration tool.
According to a Riverbed study, 64% of US employees are now working from home because of the Covid pandemic.
In turn, Microsoft Teams optimization has become a critical topic for Operations and Network personnel. As work shifts to a new environment setting, executives report that at least half of their distributed workforce consistently experiences poor experiences with SaaS apps. The phenomenal growth of Teams has resulted in video call rates increasing by over 1000% in recent months.
However, outages have found a way to plague Teams causing disruptions during meetings and broadcasts. In this unprecedented era, the continued success of Teams operations relies on monitoring and managing quality metrics in real-time.
Monitoring Teams Outside the Control Zone
Monitoring and optimizing Microsoft Teams for superior end-user experience requires a comprehensive strategy.
If I were you, I would be measuring four critical parameters – transit quality, bandwidth, capacity, and frequent change. Use these parameters to quickly determine what affects users and whether the problem lies with Teams or your own network. Nevertheless, achieving this task is difficult if monitoring is outside the control zone.
Employees are geographically distributed, and endpoints differ in each home setting. Connecting to Teams or various SaaS services requires multiple networks, protocols, and each connection has a different network configuration.
Consequently, this presents a unique challenge for IT as they have no visibility and zero control. Yet, support teams are accountable for ensuring that business-critical enterprise applications are up and running and end-users have the best digital experience.
Connecting to the Teams Architecture
As enterprises continue to hire remote employees for diversity, it becomes critical to understand how these employee’s log into the Teams infrastructure. A typical Microsoft Teams call meeting has a host and several participants. Considering this, one must evaluate success factors in terms of the locations where all the participants will be joining vs where the host would be streaming AV from.
When a meeting participant connects from India to a host meeting in the US, the participant connects to the nearest Microsoft media/relay server from their location through the nearest front door into the Azure backbone infrastructure. The host starts the video, and this traffic leads back to the participants via the same route.
Before optimizing Teams performance, it becomes critical to understand baseline metrics at these sites where IT can observe the real-time quality of AV.
Even the Best Fail at Times
But can Microsoft Call Quality Dashboard (CQD) tool help achieve baseline goals? CQD can provide a snapshot of data quality during the assessment phase by keeping tabs on each user, each call, and each meeting. Moreover, as networks and underlying infrastructure change, this impacts Teams experience for everyone.
New changes include additional capacity, gateways, accelerators, SD-WAN, etc. while others can be due to a human error component. CQD warns only after a change has improved or deteriorated and remote workers continue to experience issues.
What CQD lacks is collecting data from real Teams sessions in real-time from critical vantage points. In the event of an outage, call failure, or poor AV quality, the IT team needs proactive notifications.
By providing instant access to hop-by-hop context data, support teams can quickly identify if the actual problem lies with Microsoft, ISP, or their own network.
Teams Quality of Service (QoS) Benchmarks
Latency, packet loss, jitter, bandwidth, service quality, etc. are few metrics to measure when it comes to Teams. Gaining better control of these metrics can contribute to a superior experience.
However, CQD displays outdated evaluation data and impairs decision-making for IT who are concerned if their network can deliver the metrics consistently and not just during the assessment.
The fallout from this is expecting calls from irate customers having issues logging in or with poor Teams AV quality. There should be an easier and preferred way for IT to quickly determine whether they are meeting their call quality goals.
Below are basic benchmarks for optimizing and delivering an optimal Teams experience for a digital hybrid workforce.
- Mean (avg) Audi Jitter < 20ms
- Round Trip Latency < 100ms
- Packet Loss < 1%
- Audio Bandwidth > 100Kbps
- Video Bandwidth > 300 Kbps
How to Monitor Microsoft Teams AV Performance
Learn how to monitor Teams audio-video jitter, packet loss, response time, and other metrics. Ensure high call quality service metrics and deliver a great end-user digital experience.
2 Ways to Optimize Microsoft Teams Performance and Availability
Just installing Microsoft Teams in your environment is the beginning. You need a fully optimized and high performance from Microsoft Teams so your remote knowledge workers stay productive and efficient. At Exoprise, we offer two ways to monitor Teams, synthetic and real user monitoring (RUM) that forms part of our Digital Experience Monitoring strategy.
Synthetic Transaction Monitoring to Optimize Network Traffic and Connectivity
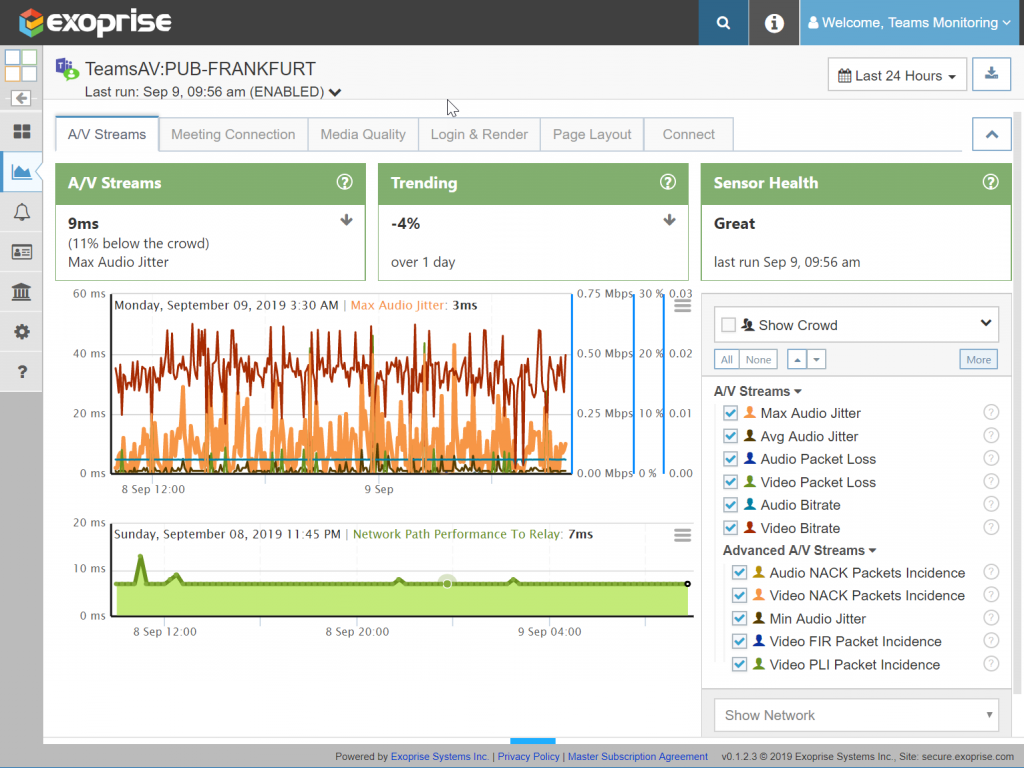
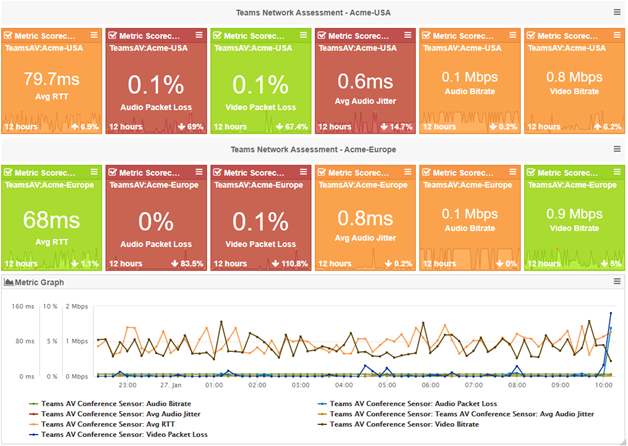
CloudReady synthetic monitoring delivers Teams metrics data in real-time, enabling IT to easily estimate availability and performance. Below is a screenshot that shows exactly what readings are for these critical metrics. Companies can confidently respond to whether they are effectively monitoring remote, WFH, and branch office employee experience needs.
By using sensors at strategic vantage points that are met every few minutes, CloudReady captures real-time end-to-end communication statistics 24*7 and 365 days a year. The number of sensors a company needs to deploy depends on how far it needs to cast a network to raise the alarm about any problems.
IT can start immediately by simply deploying a few sensors in the data center, at headquarters, or for remote employees from any Windows machine on any network. If a problem happens and there are no issues reported from vantage points, then Microsoft is the main culprit.
Endpoint Monitoring to Detect Slowness and Crashing for the Microsoft Teams Desktop App
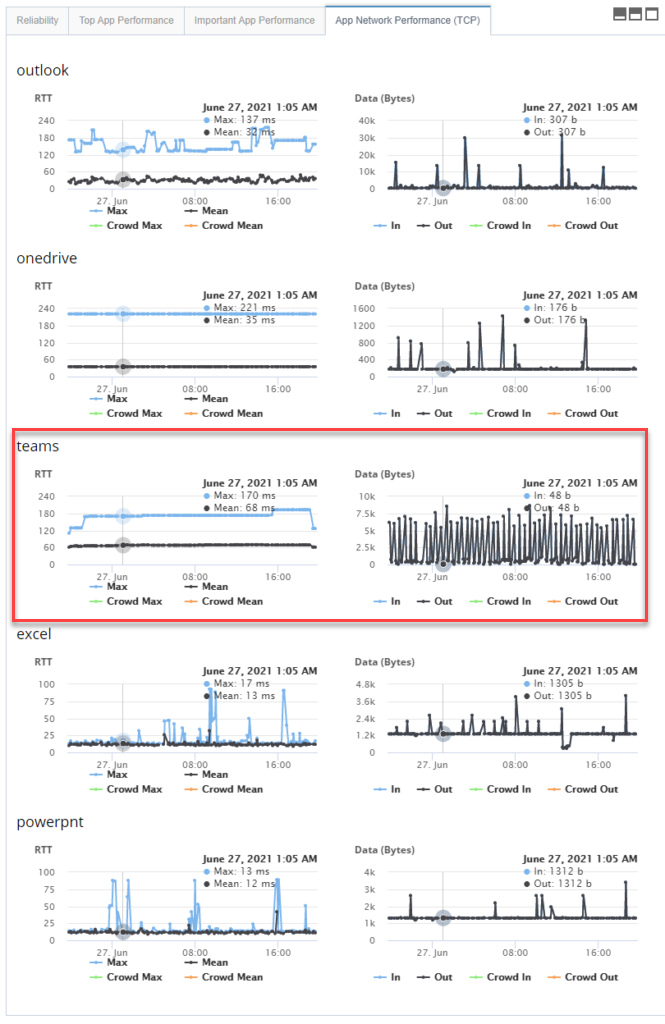
The other possibility of optimizing Teams experience for your remote workers is through Service Watch Desktop. This real user monitoring solution from Exoprise tracks network response time, latency, and round trip time (RTT) for the individual Desktop Teams app. When Teams is performing slow, IT can look into the RTT metric for that particular user endpoint and compare it against the crowd. That right there offers actionable insight and valuable information if the problems lie with the entire remote workforce or a single endpoint device. Possible reasons for the high response time could be heavily congested traffic.
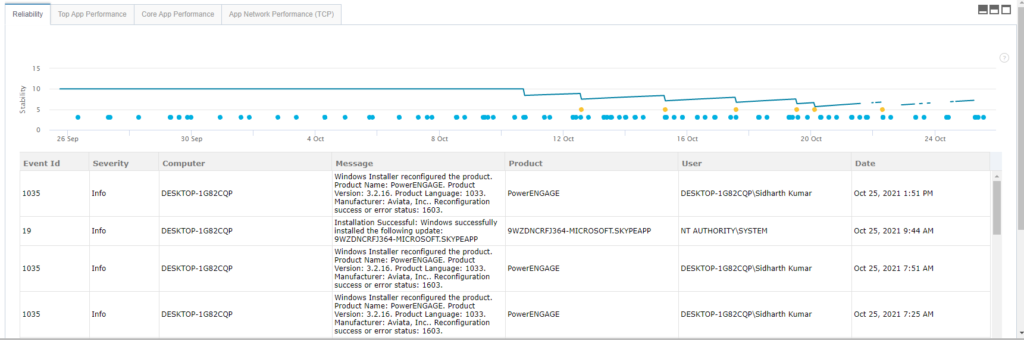
In addition, if the Teams Desktop app is frequently crashing, support teams and network administrators can get vital clues under the Reliability tab. Service Watch captures all the event information details from the OS kernel here. Discover the trigger source in the form of program updates/upgrades by the end-user that’s causing the Teams application to crash, freeze, or hang. Rolling back the installation and retrying the app can work the trick, thereby reducing several manhours of investigation and troubleshooting Teams crash issues. You can also investigate high Teams CPU and memory resource utilization under different tabs (Core App Performance) and monitor usage trends over a select period. Now you have the visibility and know what’s causing the issue with Teams, phew!
Always Be Monitoring to Improve Teams Performance
Testing before changes (for baselines), after changes (to confirm if any new network upgrades improved or broke the benchmark), and continuous monitoring in production, becomes a central part of IT monitoring strategy.
But exceptionally when outages occur, Exoprise treats them better than others. A few days ago, and as always, CloudReady detected the Exchange Online and Microsoft 365 issue 2 hours before Microsoft acknowledged the problem on their site.
Teams AV testing under conditions (public or private sites) that reflect exactly what end-users are experiencing establishes the monitoring and troubleshooting process as more valuable. Monitoring of Teams WebRTC/AV stats from cloud sites isn’t really while everyone WFH today. On the other hand, Teams messaging, and availability monitoring of Teams run from Exoprise global public vantage sites.
The combination of CloudReady and Service Watch helps to provide a complete overview of the user experience along with a high-level insight into the health of the network infrastructure. Don’t believe us? Check out our video with Forrester.
Microsoft Teams Notifications to Optimize Performance
See what Exoprise can do for your enterprise with a simple deployment. View how an IT administrator can easily track all QoS and call quality metrics. Immediately detect network issues impacting your next Team audio-video call and receive timely notifications in ServiceNow. Ensure low latency and a high-quality end-user experience for your remote workers.
Keep in mind that Microsoft will keep adding new Teams features and will have service delivery issues. Whether employees use the desktop or web app, it is your responsibility to optimize Microsoft Teams performance.
And don’t forget to signup for a free 15-day trial for Microsoft Teams monitoring.
Related Posts


